No More Babel?
Exploiting word commonalities could accelerate development of automatic translators.
Despite tens of millions of dollars invested by the Department of Defense on automatic translation systems, Americans stationed in Iraq still rely almost entirely on human translators to communicate with the Arab-speaking population. The slow deployment of translation devices stands as evidence of just how difficult and time consuming it is to develop a technology that can reliably convert speech from one language to another. Wade Shen and Brian Delaney, electrical engineers in Lincoln Laboratory’s Information Systems Technology group, are leading work that could significantly shorten the time needed to get automatic translation capabilities into the field. Eventually, efforts such as Shen’s could make possible a machine that emulates the Babel fish—the fanciful creature, described in Douglas Adams’s Hitchhiker’s Guide to the Galaxy series, that translates in real time between any two spoken languages.
Shen says that the machine translators available today have limited utility. They are adequate, he says, for enabling monolingual individuals to carry out simple exchanges in a foreign tongue—for example, asking for directions or ordering from a menu. Such systems, he says, “are typically most useful in communications requiring a very limited vocabulary.” Today’s technology relies on statistical methods to learn word-for-word and phrase-for-phrase translations; the translation system functions as an enormous automated phrase book. These systems need large quantities of training data—the set of sentence pairs in a language that is available for translation—and they lack breadth of vocabulary and grammatical sophistication. Furthermore, such systems are imperfect in producing translated text with words in the proper order, a deficiency that Shen and his colleagues plan to address.
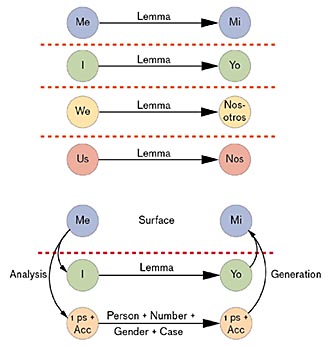 Morphology-based speech analysis enables machine translation with a smaller database of sentences. At top, without using morphology, me translates into the Spanish mi, but there is no built-in correlation to match I with yo. Using Shen’s methods (bottom), the base word I translates to yo, and all other correlated words (me, my, we, us, our) would be translated through their person (ps) and accusative cases. Lincoln Laboratory’s focus is defined by the following hypothetical scenario, as laid out by the Department of Defense: A conflict has erupted in a country where the U.S. government has no human or machine translators. There are, however, some number of sentences and phrases in the country’s language that have been translated. Given this situation, how quickly can this linguistic information be used to create automatic translation devices?
Shen, working under an Air Force contract, is chiefly aiming to reduce the large volumes of training data needed while he still maintains an automated large-vocabulary phrase book. In the end, his task boils down to statistics. How can you verify that a word or phrase in one language has been translated correctly into another? Shen is applying sophisticated grammatical connections between words and phrases to produce translation algorithms that use a greatly reduced quantity of training data. Consider, Shen says, the concept of plural nouns: “Even if you have a limited sample of translated sentences, if you see the word mine in English and you see mina in Spanish in sufficient numbers, you can be fairly certain that mine translates to mina.” In most cases, plurals are treated separately—an additional set of training phrases are required to match ours to el nuestros. “We want to eliminate this problem by using much smaller amounts of data in a smarter way,” Shen says.
As part of an international effort involving sites in Italy, Britain, and the Czech Republic, as well as in the United States, Shen and his colleagues have devised models that attempt to make better use of this linguistic information. In these models, words are decomposed into morphological parts (e.g., houses = house + [plural], running = run + [progressive]). Each part is treated separately during translation. Next, a smaller database of translations collects richer statistics, since concurrent phrases or terms can be combined across different inflected forms (i.e., ran, run, and running all contribute to the count of the base form run). During translation, the input words are decomposed in the source language into parts. These parts are translated separately, and then recombined in the target language. The linguistic knowledge needed for the decomposition/combination processes can be learned by using statistical methods with much less data than would be required for all possible inflected forms.
For validation, Shen ran experiments by building morphology-based systems that translated English to Spanish that were trained with transcripts of European Parliament sessions. These transcripts contained some 40,000 sentence pairs, or only about 5% of a normal training set. He then compared the performance of standard translation methods that make no use of morphology—in one case using the same 40,000 sentence pairs, in another case using 750,000 sentence pairs. Shen found that the morphology-based translation approaches the performance of standard systems trained on nearly 20 times the data. The validation confirms that his translation algorithms work as effectively as he expected.
Many other linguistic generalizations could also be applied toward the translation problem. Shen’s current effort, for example, attempts to incorporate syntactic information in addition to word morphology. In doing so, Shen and his associates hope to be able to resolve grammatical problems that arise from poor word ordering. This is a particularly tricky problem when translating from languages such as Japanese, where word order is relatively unconstrained. The team is extending its work in evaluation tools in preparation for the National Institute of Standards and Technology evaluation machine translation technologies for Less-Commonly Taught Languages (LCTL), to be held this fall.
Even with his advances, Shen says, we are still far from solving the machine translation problem. “We’re still at the beginning stages of effectively utilizing linguistic knowledge in the translation process,” he says. Asked about the possibility of a babelfish-like personal headset that performs instantaneous speech-to-speech translation, Shen is cautious. “In fifty years, we’ll have something like that,” he says. “Maybe.” |